Un sistema de inteligencia artificial alcanzó el nivel humano en test de “inteligencia general”: esto es lo que pasará ahora
El sistema o3 de OpenAI superó la puntuación en una prueba estándar muy por encima de la mejor puntuación obtenida anteriormente por IA.

Un nuevo modelo de inteligencia artificial (IA) acaba de lograr resultados de nivel humano en una prueba diseñada para medir la “inteligencia general”.
El 20 de diciembre, el sistema o3 de OpenAI obtuvo una puntuación del 85% en el índice de referencia ARC-AGI, muy por encima de la mejor puntuación obtenida anteriormente por IA, del 55%, y a la par de la puntuación media humana. También obtuvo una buena puntuación en una prueba de matemáticas muy difícil.
Un sistema de inteligencia artificial alcanzó el nivel humano en test de “inteligencia general”: esto es lo que pasará ahora
La creación de inteligencia artificial general, o AGI, es el objetivo declarado de todos los principales laboratorios de investigación en IA. A primera vista, OpenAI parece haber dado al menos un paso significativo hacia este objetivo.
Aunque el escepticismo persiste, muchos investigadores y desarrolladores de IA tienen la sensación de que algo acaba de cambiar. Para muchos, la perspectiva de la IAG ahora parece más real, urgente y cercana de lo que se esperaba. ¿Tienen razón?
Para entender qué significa el resultado o3, es necesario comprender de qué se trata la prueba ARC-AGI. En términos técnicos, es una prueba de la “eficiencia de muestra” de un sistema de IA para adaptarse a algo nuevo: cuántos ejemplos de una situación nueva necesita ver el sistema para descubrir cómo funciona.
Un sistema de IA como ChatGPT (GPT-4) no es muy eficiente en cuanto a la selección de muestras. Fue “entrenado” con millones de ejemplos de textos humanos y construyó “reglas” probabilísticas sobre qué combinaciones de palabras son más probables.
El resultado es bastante bueno en tareas comunes, pero malo en tareas poco comunes, porque tiene menos datos (menos muestras) sobre esas tareas.

Hasta que los sistemas de IA puedan aprender de pequeñas cantidades de ejemplos y adaptarse con mayor eficiencia, solo se utilizarán para trabajos muy repetitivos y en los que el fallo ocasional sea tolerable.
La capacidad de resolver con precisión problemas previamente desconocidos o nuevos a partir de muestras limitadas de datos se conoce como capacidad de generalización y se considera un elemento necesario, incluso fundamental, de la inteligencia.
Cuadrículas y patrones
El benchmark ARC-AGI prueba la adaptación eficiente de la muestra utilizando pequeños problemas de cuadrícula como el que se muestra a continuación. La IA debe descubrir el patrón que convierte la cuadrícula de la izquierda en la cuadrícula de la derecha.
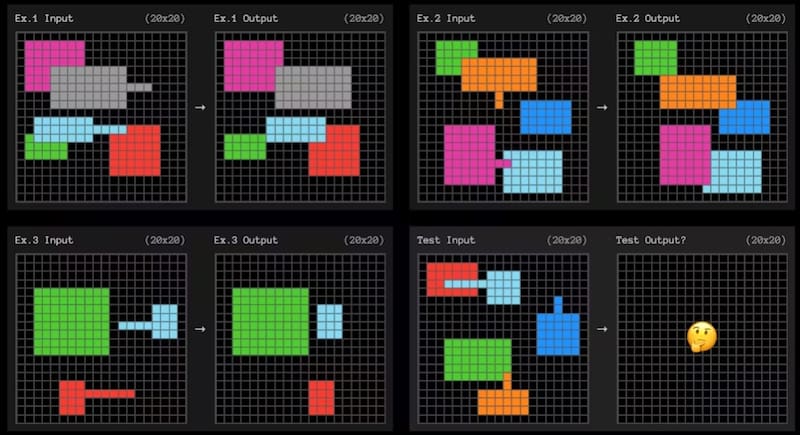
Cada pregunta ofrece tres ejemplos de los que aprender. El sistema de IA debe determinar las reglas que se “generalizan” a partir de los tres ejemplos para el cuarto.
Son muy similares a las pruebas de coeficiente intelectual que quizás recuerdes de la escuela.
Normas débiles y adaptación
No sabemos exactamente cómo lo ha hecho OpenAI, pero los resultados sugieren que el modelo o3 es muy adaptable. A partir de unos pocos ejemplos, encuentra reglas que se pueden generalizar.
Para identificar un patrón, no deberíamos hacer suposiciones innecesarias ni ser más específicos de lo que realmente debemos ser. En teoría, si puedes identificar las reglas “más débiles” que hacen lo que quieres, entonces habrás maximizado tu capacidad de adaptarte a nuevas situaciones.
¿Qué queremos decir con las reglas más débiles? La definición técnica es complicada, pero las reglas más débiles suelen ser aquellas que se pueden describir con enunciados más simples.
En el ejemplo anterior, una expresión sencilla en inglés de la regla podría ser algo como: “Cualquier forma con una línea saliente se moverá al final de esa línea y ‘cubrirá’ cualquier otra forma con la que se superponga”.
¿Buscando cadenas de pensamiento?
Si bien aún no sabemos cómo OpenAI logró este resultado, parece poco probable que hayan optimizado deliberadamente el sistema o3 para encontrar reglas débiles. Sin embargo, para tener éxito en las tareas de ARC-AGI, deben encontrarlas.
Sabemos que OpenAI comenzó con una versión de propósito general del modelo o3 (que se diferencia de la mayoría de los otros modelos porque puede dedicar más tiempo a “pensar” en preguntas difíciles) y luego lo entrenó específicamente para la prueba ARC-AGI.
El investigador francés de inteligencia artificial François Chollet, que diseñó el punto de referencia, cree que o3 busca en distintas “cadenas de pensamiento” que describen los pasos para resolver la tarea. Luego elegiría la “mejor” según una regla poco definida o “heurística”.
Esto no sería muy diferente a cómo el sistema AlphaGo de Google buscaba diferentes secuencias posibles de movimientos para vencer al campeón mundial de Go.

Se puede pensar en estas cadenas de pensamiento como programas que se ajustan a los ejemplos. Por supuesto, si es como la IA que juega al Go, entonces necesita una heurística, o una regla flexible, para decidir qué programa es mejor.
Se podrían generar miles de programas aparentemente igualmente válidos. Esa heurística podría ser “elegir el más débil” o “elegir el más simple”.
Sin embargo, si es como AlphaGo, entonces simplemente hicieron que una IA creara una heurística. Este fue el proceso para AlphaGo. Google entrenó un modelo para calificar diferentes secuencias de movimientos como mejores o peores que otras.
Lo que aún no sabemos
La pregunta entonces es: ¿esto realmente se acerca más a la inteligencia artificial general? Si así es cómo funciona el o3, entonces el modelo subyacente podría no ser mucho mejor que los modelos anteriores.
Los conceptos que el modelo aprende del lenguaje podrían no ser más adecuados para la generalización que antes. En cambio, es posible que simplemente estemos viendo una “cadena de pensamiento” más generalizable que se encuentra a través de los pasos adicionales de entrenamiento de una heurística especializada para esta prueba. La prueba, como siempre, estará en el pudin.
Casi todo lo relacionado con el o3 sigue siendo desconocido. OpenAI ha limitado la divulgación a unas pocas presentaciones en los medios y las primeras pruebas a un puñado de investigadores, laboratorios e instituciones de seguridad de la IA.
Comprender verdaderamente el potencial del o3 requerirá un trabajo extenso, que incluye evaluaciones, una comprensión de la distribución de sus capacidades, con qué frecuencia falla y con qué frecuencia tiene éxito.
Cuando finalmente se lance o3, tendremos una idea mucho mejor de si es aproximadamente tan adaptable como un humano promedio.
De ser así, podría tener un enorme impacto económico revolucionario, que marcaría el inicio de una nueva era de inteligencia acelerada y automejorada. Necesitaremos nuevos parámetros de referencia para la propia IAG y una seria reflexión sobre cómo debería gobernarse.
Si no, el resultado será igualmente impresionante, pero la vida cotidiana seguirá siendo prácticamente la misma.
*Michael Timothy Bennett, estudiante de doctorado, Facultad de Informática, Universidad Nacional de Australia
**Elija Perrier, investigador asociado, Centro de Stanford para la Tecnología Cuántica Responsable, Universidad de Stanford
COMENTARIOS
Para comentar este artículo debes ser suscriptor.
Lo Último
Lo más leído





No sigas informándote a medias 🔍
Accede al análisis y contexto que marca la diferenciaNUEVO PLAN DIGITAL $1.990/mes SUSCRÍBETE












